MTCNN做人脸检测和对齐
将需要识别的含有人脸的图片放在’./images/test_img’,代码首先使用detection_face_and_crop对提供的人脸图像进行预处理(人脸检测和对齐),将预处理之后的人脸图像存放到’./images/emb_img’目录下。
三个重要参数:
minisize: 图片中人脸的最小尺寸,控制人脸金字塔阶数参数之一,其值越小,可计算的阶数越多,计算量越大。
threhold: MTCNN中三个网络人脸框的阈值,三个阈值可以分别设置,这里分别设置为0.6、0.7、0.7。阈值太小将会导致人脸框太多,增加计算量;还可能导致不是人脸的图像检测为人脸。
factor: 生成图像金字塔时候的缩放系数, 范围(0,1),可控制图像金字塔的阶层数的参数之一,越大,阶层越多,计算量越大。
detect_face()返回值为人脸框的坐标以及是人脸的概率。
动态分配显存
1 | config = tf.ConfigProto() |
detection_face_and_crop.py代码如下:
1 | from cv2 import cv2 |
利用facenet和mtcnn做人脸识别
利用opencv调取电脑或者网络摄像头,也可以读取视频进行识别。
读取网络摄像头,当使用本地摄像头时,VideoCapture()参数设置为“0”:1
2video="http://admin:admin@192.168.137.33:8081/"
capture =cv2.VideoCapture(video)
读取视频同时设置读入视频的宽高和帧率1
2
3
4
5dirVideo = "video1.mp4"
capture =cv2.VideoCapture(dirVideo)
capture.set(cv2.CAP_PROP_FRAME_WIDTH, 1920)
capture.set(cv2.CAP_PROP_FRAME_HEIGHT, 1080)
capture.set(cv2.CAP_PROP_FPS, 60)
当需要将opencv的视频输出时,使用opencv的VideoWriter()输出视频:1
2
3size = (int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)), int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT)))
fourcc = cv2.VideoWriter_fourcc(*'XVID')
writeVideo = cv2.VideoWriter('output.avi',fourcc, 20, size, 1)
这里以一个短视频人脸识别为例,首先将原视频输入,利用opencv获取视频帧,这里是将原视频中每三帧取一帧来做人脸距离计算。主要过程是将opencv读取的画面做人脸检测和对齐(使用MTCNN网络),再将得到的人脸图像和从emb_img中读取的包含人脸的图像做距离计算,将距离小于阈值的图像对应的标签放到列表。最后就是在视频中绘制人脸框并将对应的标签显示在框上,最终效果如下图: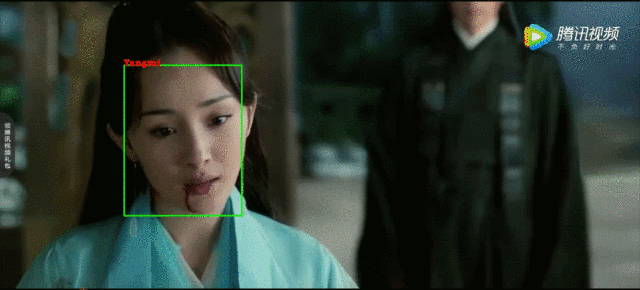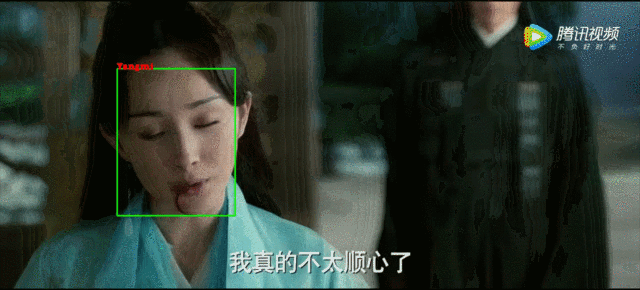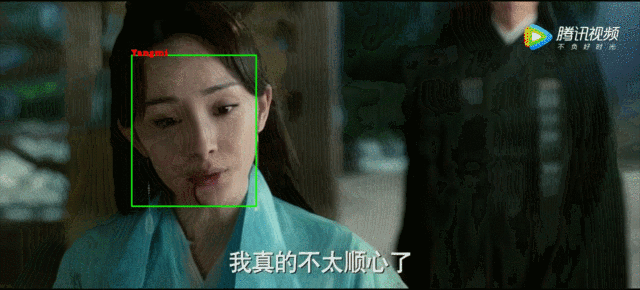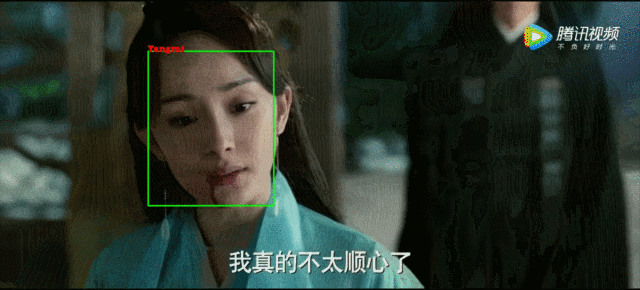
完整源代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71# video="http://admin:admin@192.168.137.33:8081/"
# capture =cv2.VideoCapture(video)
dirVideo = "video1.mp4"
capture =cv2.VideoCapture(dirVideo)
# capture.set(cv2.CAP_PROP_FRAME_WIDTH, 1920)
# capture.set(cv2.CAP_PROP_FRAME_HEIGHT, 1080)
capture.set(cv2.CAP_PROP_FPS, 60)
# size =(int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)),int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)))
# fourcc = cv2.VideoWriter_fourcc('M','J','P','G')
# writeVideo = cv2.VideoWriter("aaa.avi", fourcc, 5, size)
# size = (int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)), int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT)))
# fourcc = cv2.VideoWriter_fourcc(*'XVID')
# writeVideo = cv2.VideoWriter('output.avi',fourcc, 20, size, 1)
cv2.namedWindow("camera",1)
picNumber = 0
count = 0
frame_interval = 3
while True:
isSuccess, frame = capture.read()
if(count % frame_interval == 0):
rgb_frame=cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
tag, bounding_box, crop_image, =load_and_align_data(rgb_frame,160,44)
if(tag):
feed_dict = { images_placeholder: crop_image, phase_train_placeholder:False }
emb = sess.run(embeddings, feed_dict=feed_dict)
print(emb)
temp_num=len(emb)
fin_obj=[]
# calculate distance between camera face and in emd_img face
for i in range(temp_num):
dist_list=[]
for j in range(compare_num):
dist = np.sqrt(np.sum(np.square(np.subtract(emb[i,:], compare_emb[j,:]))))
dist_list.append(dist)
min_value=min(dist_list)
if(min_value>0.65):
fin_obj.append('UNKNOW')
else:
fin_obj.append(all_obj[dist_list.index(min_value)][0:6]) #mini distance is face which recongnition
# draw rectangle
for rec_position in range(temp_num):
cv2.rectangle(frame,
(bounding_box[rec_position,0],
bounding_box[rec_position,1]),
(bounding_box[rec_position,2],
bounding_box[rec_position,3]),
(0, 255, 0), 2, 8, 0)
cv2.putText(frame,
fin_obj[rec_position],
(bounding_box[rec_position,0],bounding_box[rec_position,1]),
cv2.FONT_HERSHEY_COMPLEX_SMALL,
0.8,
(0, 0 ,255),
thickness = 2,
lineType = 2)
# writeVideo.write(frame)
cv2.imshow('camera',frame)
count += 1
key = cv2.waitKey(3)
if key == 27:
print("ESC break")
break
if key == ord(' '):
picNumber += 1
# filename = "{}_{}.jpg".format(dirVideo, picNumber)
filename = "%s_%s.jpg" % (dirVideo, picNumber)
cv2.imwrite(filename,frame)
capture.release()
cv2.destroyWindow("camera")