什么是人脸检测和人脸对齐?
人脸检测,顾名思义,就是在检测一张图片中检测有没有人脸,找出人脸的位置。人脸检测的过程即输入一张可能含有人脸的图片,然后输出人脸的位置。但是由于人脸可能出现在原始图片中的任何地方,人脸的姿势可能都很大的区别,为了便于统一处理,需要进行人脸对齐。这个过程中需要检测人脸中的关键点,例如:眼睛、鼻子、嘴巴等等,利用这些关键点可以做仿射变换将人脸校正,消除位置、姿势带来的误差。
MTCNN(Multi-task CNN)简介
MTCNN是一种基于深度卷积神经网络的人脸检测和人脸对齐的方法。它由三个神经网络组成,分别是P-NET、R-NET、O-NET。由于原始图片中的人脸存在不同的尺度,例如有的人脸大,有的人脸小。对应比较小的人脸,可以将其放大再进行检测;而对于比较大的人脸,可以将其缩小后再进行检测。这样就可以保证在相同的尺度下检测人脸。因此,在使用MTCNN之前需要将原始的图片缩放到不同的尺度,形成一个“图像金字塔”(如下图),紧接着将对每一个尺度的图像都利用神经网络计算一遍。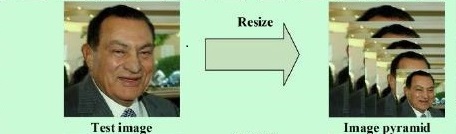
P-Net:
P-Net网络的结构如下图: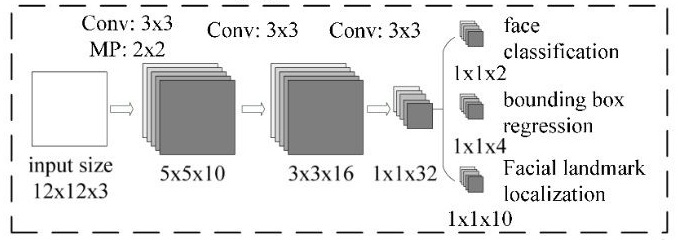
P-NET网络的输入是一个12×12×3的图像,P-NET的工作就是判断这个12×12的图像中是否有人脸,并且给出人脸框和关键点。网络的输出主要也三部分组成:即上图中的face classification、bounding box regression、Facial landmark localization。
face classification是一个1×1×2的向量,即输出为两个值,分别是该图像是人脸的概率和该图像不是人脸的概率,这里利用两个值来表示,可以很方便的表示交叉熵损失。
bounding box regression是人脸框的精确位置,即框回归。bounding box regression是一个1×1×4的向量,因为对于图像中的框的表示方法,一般是采用四个数来表示它的位置(框左上角的横坐标、框左上角的纵坐标、框的宽度、框的高度)。网络输入的图像中的人脸可能不是一个完美的矩形,可能会有左右偏移,因此需要输出当前框相对于完美人脸框的偏移,由四个变量组成。在进行框回归输出的时候,需要输出框左上角横坐标的相对偏移、框左上角纵坐标的相对偏移、框宽度的误差、框高度的误差。
Facial landmark localization是一个1×1×10的向量,它表示的是人脸上的五个关键点:左眼、右眼、鼻子、左嘴角、右嘴角,每个关键点都有横坐标和纵坐标,因此这是一个10维向量。
在实际的计算中,通过P-NET中的第一层卷积的移动,会对图像中的每一个12×12区域都做一次人脸检测。
下图展示了“图像金字塔”经过P-Net初步筛选后的结果,计算输出的框的大小是各不相同的,这是因为P-NET计算了图片金字塔中的每一个尺度。
tensorflow代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class PNet(Network):
def setup(self):
(self.feed('data') #pylint: disable=no-value-for-parameter, no-member
.conv(3, 3, 10, 1, 1, padding='VALID', relu=False, name='conv1')
.prelu(name='PReLU1')
.max_pool(2, 2, 2, 2, name='pool1')
.conv(3, 3, 16, 1, 1, padding='VALID', relu=False, name='conv2')
.prelu(name='PReLU2')
.conv(3, 3, 32, 1, 1, padding='VALID', relu=False, name='conv3')
.prelu(name='PReLU3')
.conv(1, 1, 2, 1, 1, relu=False, name='conv4-1')
.softmax(3,name='prob1'))
(self.feed('PReLU3') #pylint: disable=no-value-for-parameter
.conv(1, 1, 4, 1, 1, relu=False, name='conv4-2'))
R-Net:
R-Net网络的结构如下图: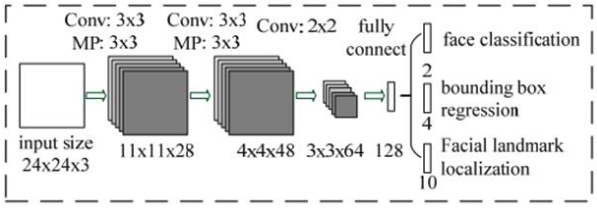
从P-Net的结果可以看到P-NET的输出是很粗糙的,因此利用R-NET对P-NET的进行调优。R-NET的输入是24×24×3的图像,即R-NET将判断24×24×3的图像中是否含有人脸,预测关键点的位置,它的输出和P-NET一样,包括:face classification、bounding box regression、Facial landmark localization。
但是这里R-NET的输入是P-NET的输出中可能为人脸的区域,将这些区域缩放成24×24×3的大小,利用R-NET作进一步判定,消除P-NET产生的一些误判,如下图:

经过R-Net消除一些误判,人脸框将在P-Net基础上减少。
tensorflow代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class RNet(Network):
def setup(self):
(self.feed('data') #pylint: disable=no-value-for-parameter, no-member
.conv(3, 3, 28, 1, 1, padding='VALID', relu=False, name='conv1')
.prelu(name='prelu1')
.max_pool(3, 3, 2, 2, name='pool1')
.conv(3, 3, 48, 1, 1, padding='VALID', relu=False, name='conv2')
.prelu(name='prelu2')
.max_pool(3, 3, 2, 2, padding='VALID', name='pool2')
.conv(2, 2, 64, 1, 1, padding='VALID', relu=False, name='conv3')
.prelu(name='prelu3')
.fc(128, relu=False, name='conv4')
.prelu(name='prelu4')
.fc(2, relu=False, name='conv5-1')
.softmax(1,name='prob1'))
(self.feed('prelu4') #pylint: disable=no-value-for-parameter
.fc(4, relu=False, name='conv5-2'))
P-Net:
O-Net网络的结构如下图: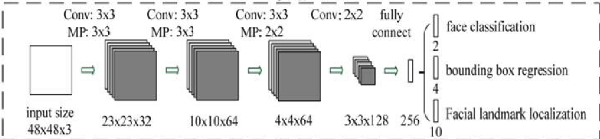
相对于P-NET,O-NET网络的通道数和层数更多。同之前的处理类似,进一步把得到的区域做一个缩放处理,缩放成48×48的大小,输入到最后的O-NET网络。
经过最后的O-Net的处理,误判人脸框将进一步减少。
tensorflow代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class ONet(Network):
def setup(self):
(self.feed('data') #pylint: disable=no-value-for-parameter, no-member
.conv(3, 3, 32, 1, 1, padding='VALID', relu=False, name='conv1')
.prelu(name='prelu1')
.max_pool(3, 3, 2, 2, name='pool1')
.conv(3, 3, 64, 1, 1, padding='VALID', relu=False, name='conv2')
.prelu(name='prelu2')
.max_pool(3, 3, 2, 2, padding='VALID', name='pool2')
.conv(3, 3, 64, 1, 1, padding='VALID', relu=False, name='conv3')
.prelu(name='prelu3')
.max_pool(2, 2, 2, 2, name='pool3')
.conv(2, 2, 128, 1, 1, padding='VALID', relu=False, name='conv4')
.prelu(name='prelu4')
.fc(256, relu=False, name='conv5')
.prelu(name='prelu5')
.fc(2, relu=False, name='conv6-1')
.softmax(1, name='prob1'))
(self.feed('prelu5') #pylint: disable=no-value-for-parameter
.fc(4, relu=False, name='conv6-2'))
(self.feed('prelu5') #pylint: disable=no-value-for-parameter
.fc(10, relu=False, name='conv6-3'))
MTCNN的处理过程,从P-NET到N-NET,最后再到O-NET,网络输入的图片越来越大,卷积层的通道数越来越多,内部层数也越来越多,它对人脸的识别率也越来越高。还可以看出从P-NET到O-NET的运行速度越来越慢。正是由于O-NET的速度最慢,因此不直接使用O-NET,而是先用P-NET和R-NET层层过滤,减少待判别的数量,提高网络处理的速度,降低处理时间。