目标检测器从端到端学习范式中获益匪浅。推荐、特征和分类器成为一个神经网络将通用的目标检测的精度提高了2倍。另外一个不可或缺的组成部分就是非极大值抑制算法(non-maximum suppression,NMS),一种后处理算法,主要用于负责合并同一对象的所有检测结果。
目标检测步骤
所有的目标检测器都经过以下三个步骤:
1)利用滑动窗口提取一个窗口的搜索空间(由许多边界框(bounding box)组成);
2)用分类器或者回归器对窗口进行置信度(confidence score)评估;
3)利用非极大值抑制算法合并每一个对象的边界框。
非极大值抑制算法
下面主要对非极大值抑制算法做一个简单的介绍。
如上的第一步,目前的目标检测算法会在第一步的时候,为每一个对象确定不止一个边界框,但是算法最后进行目标种类识别的时候,仅仅需要一个边界框。这个时候,我们需要去找一个最有利于目标识别的框来进行目标识别,例如下面这个例子: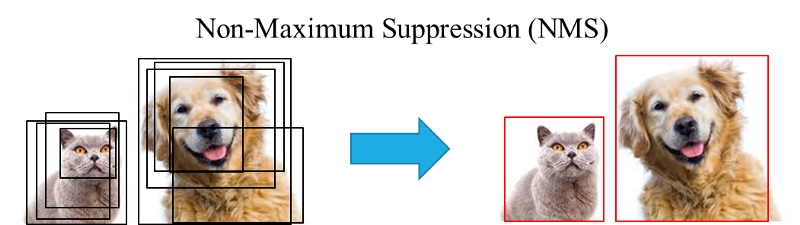
由上图可以看到算法开始可以为每一个可能的目标确定多个边界框,每个框的参数主要表示为(x,y,h,w,s)。其中(x,y)表示框的中心坐标,(h,w)表示框的高和宽,最后一个参数s指的是每个框的置信度,由上面的第二步计算得到。非极大值抑制算法需要做的就是上图从左到右的过程。
非极大值算法伪代码
算法的伪代码如下:

输入的是由第一步得到的边界框的集合B以及第二步计算得到的置信度集合S,$N_t$表示NMS的阈值。首先选取集合B中置信度最大的边界框,把此边界框从集合B做去除,加入到一个新集合D中,这个集合存放左右的保留框。然后将B集合中的每一个边界框与保留框做交并比(IOU),并将结果大于阈值$N_t$的边界框从B集合中剔除,直到B集合为空,此时所有的保留框都已经存放在集合D中了。真正进行目标检测的时候,使用的就是集合D中的保留框。
可以利用下面这个例子来体会算法的具体流程:
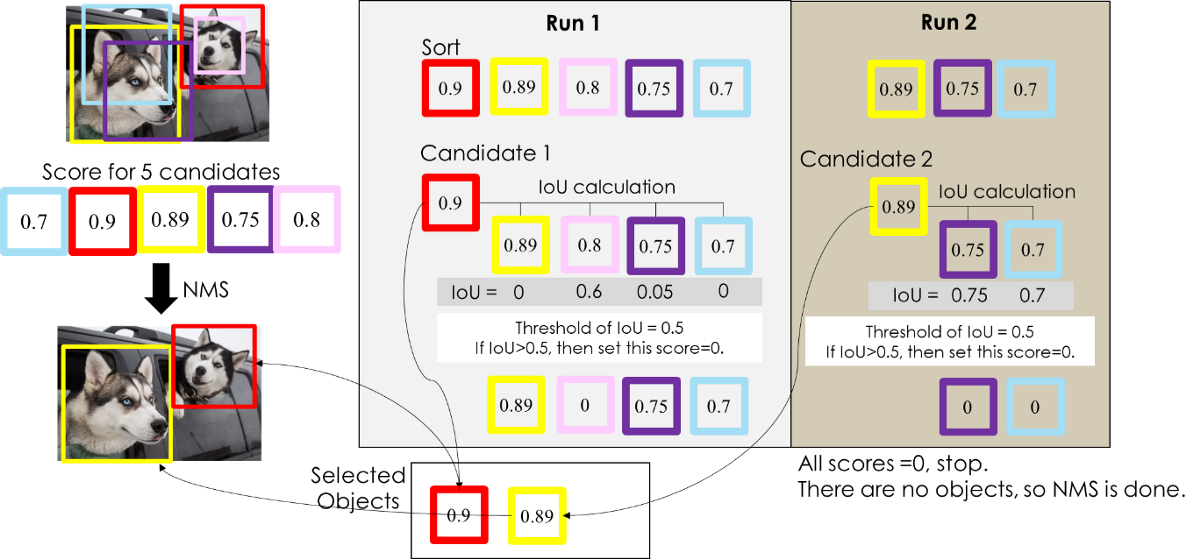
我们可以看到图中每一只狗都有各自的边界框,每个框都有各自的参数(x,y,h,w,s)。首先按照置信度S对边界框进行排序,找出置信度最大的边界框,这里找到的是置信度为0.9的红色框,将红色框从原集合B中剔除,加入到集合D中。然后将置信度为0.9的红色框与剩余的边界框做IOU,得到的结果分别是0、0.6、0.05、0,并且假设阈值为0.5,可以看到此时与粉色框的IOU = 0.6,大于阈值,此时直接剔除粉色框,即将其置信度设置为0。再从剩余的框中继续选择置信度最大的边界框,这里找到是置信度为0.89的黄色框,将黄色框从集合B中剔除,加入到保留框集合D,再将其与剩余的框做IOU,结果分别为0.75和0.7,均大于阈值,直接剔除。此时集合B为空,计算结束,可以看到我们最终得到两个边界框。
一般将阈值设置为0-0.5,阈值太大将不会有效的剔除多余的边界框,达不到过滤的效果,如下下面的这个例子:
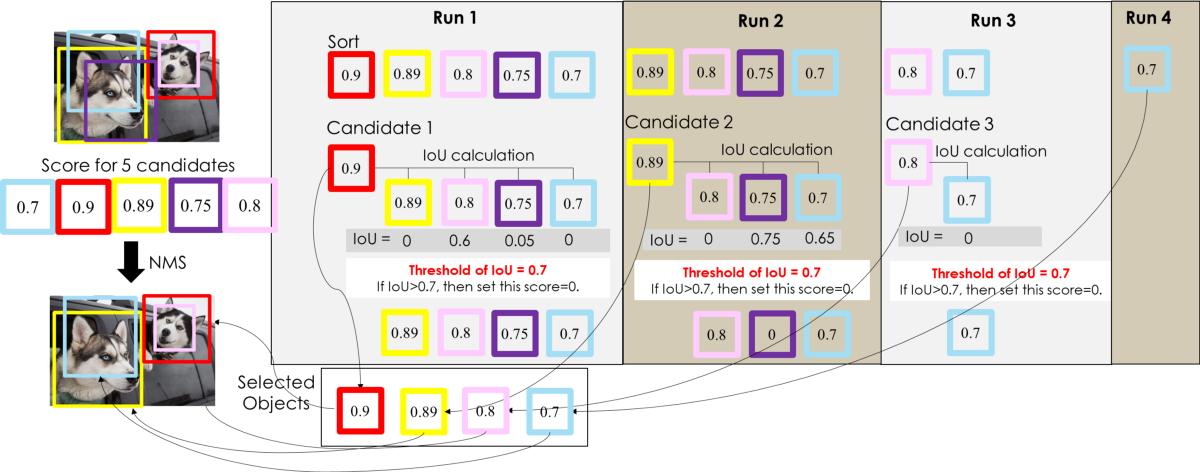
经过如上算法过程,可以看到保留框集合中,每一个目标都含有多个边界框,没有达到过滤得目的。因此,在使用NMS时,需要合理得设置阈值。
另外,如果是two stage算法,例如R-CNN系列模型,通常在选出边界框时只有(x,y,h,w,s)五个参数。这与算法得过程有关,因为算法是先选出边界框,然后将边界框与feature map做rescale,再用分类器分类。
然而对于one stage的算法,例如YOLO,SSD。边界框除了以上(x,y,h,w,s,)这五个参数,还有对应的分类概率,因此在进行计算时不用再rescale和计算分类概率,计算量更小,速度更快。